
如何才能写一篇好的微信推送?
紧跟潮流,越劲爆越好,不过要在合理范围内的(你懂得),超出的话你自己掂量。
标题要醒目!标题要醒目!标题要醒目!重要的说三遍
然后主要就是内容了,内容经可能饱满一些,如果能够让人产生共鸣就更棒了,一般人都愿意将可以产生共鸣的微信推送分享到朋友圈
推文里面的配图,段落也很重要,简洁干练让人阅读感很舒服。
加上一些独特的页首和页尾会让你的订阅号带有独特的印记,叫人能够容易记得住。
总之一篇好的推文,需要抓住一些细节。
我也正在学习当中 ,请指教呢
怎么样才能更容易让你的文章更容易获得推送 ?我总结几点 ;
1:原创
想获得平台推送的方法 ,一个很重要的因素就是文章质量高,原创性高,重复度低,
那么是更容易获得推送 ,如果你的文章和已经有发布的文章相似度很高,基本上是很难获得推送的。
2:阅读量
任何一个平台,阅读量,都是一个重要的指标 ,阅读量越高 ,那么就更容易获得平台推送 ,
不管在那个平台,都是一个非常重要的判断指标 。
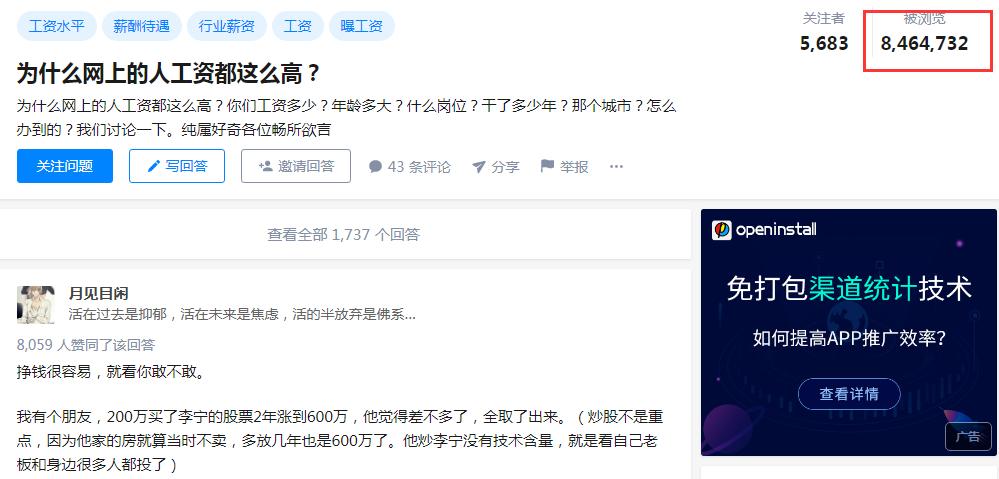
比如上图 ,这个浏览量越大,说明关心这个话题的人就越多 ,当然文章是没有阅读量的 ,这个后台是有统计的 。
看到这里,聪明的人 ,就有自己的想法了 ,那么是不是自己可以去刷阅读量呢??
这个当然是可以刷的 ,但是刷是需要一定的技术处理的 ,
你手工自己去点 是没有任何意义的 ,这里面包含好几个因素!
第一:IP分布 ,也就是点开你的链接必须是全国各地的Ip,而不是某个省市的IP ,
第二:终端分布 ,包含PC端,安卓端,苹果端
如果都满足了以上因素,那么你就可以刷阅读量 ,如果你对这方面比较感兴趣 ,也可以和我私底下 沟通。
3:评论数量
如果一篇文章,或是问答,下面非常多的评论,哪怕是很没质量,也非常的容易获得推送。
大家如果仔细观察 ,你就会发现 ,有些帖子莫名其妙的火了,虽然他的质量非常的差 ,但是因为评论非常多 。
因为有用户互动,说明这个话题比较具有争议 ,有争议性的东西,对于平台来讲,自然就乐意推送 ,
让大家一起讨论 ,一起争吵 ,所以一篇文章 或是问答写完后 ,
需要用自己的小号,进行助力推送下 ,比如小号引导讨论 ,引导对立 ,这样很多过客,非常容易停留下来 ,
参与到讨论中 ,比如我就很多小号, 几千个 大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!。
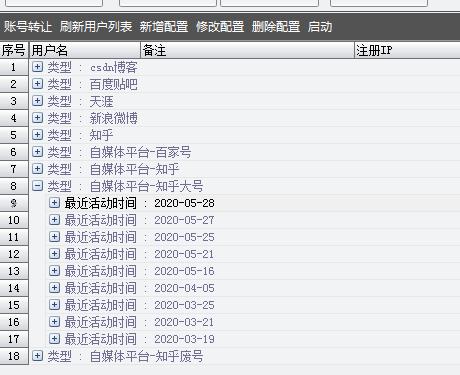
做运营,没有号 ,是很难做起来的 ,虽然说方法很多人都知道 ,但是你没有操作起来 ,号太少 ,现在号
非常的便宜,1毛一个 ,如果需要实名身份证这个也是非常容易解决的
4:标题 。
这个老生常谈 ,这个大家可以参考其他的文章 ,都写得非常详细了 ,
我就不多介绍 。
当然还有很多没有讲到的 ,这里就不细说,有兴趣 ,对引流比较感兴趣的 ,
可以一起来沟通学习
参考下图找我交流
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 1. simple plot with 4 numbers
plt.plot([1, 3, 2, 4])
plt.show()
# 2. points have x and y values; add title and axis labels
plt.plot([1, 2, 3, 4], [1, 4, 9, 16])
plt.title('Test Plot', fontsize=8, color='g')
plt.xlabel('number n')
plt.ylabel('n^2')
plt.show()
# 3. change figure size. plot red dots; set axis scales x: 0-6 and y: 0-20
plt.figure(figsize=(1,5)) # 1 inch wide x 5 inches tall
plt.plot([1, 2, 3, 4], [1, 4, 9, 16], 'ro') # red-o
plt.axis([0, 6, 0, 20]) # [xmin, xmax, ymin, ymax]
plt.annotate('square it', (3,6))
plt.show()
# 4. bar chart with four bars
plt.clf() # clear figure
x = np.arange(4)
y = [8.8, 5.2, 3.6, 5.9]
plt.xticks(x, ('Ankit', 'Hans', 'Joe', 'Flaco'))
plt.bar(x, y)
# plt.bar(x, y, color='y')
# plt.bar(x, y, color=['lime', 'r', 'k', 'tan'])
plt.show()
# 5. two sets of 10 random dots plotted
d = {'Red O' : np.random.rand(10),
'Grn X' : np.random.rand(10)}
df = pd.DataFrame(d)
df.plot(style=['ro','gx'])
plt.show()
# 6. time series - six months of random floats
ts = pd.Series(np.random.randn(180), index=pd.date_range('1/1/2018', periods=180))
df = pd.DataFrame(np.random.randn(180, 3), index=ts.index, columns=list('ABC'))
df.cumsum().plot()
plt.show()
# 7. random dots in a scatter
N = 50
x = np.random.rand(N)
y = np.random.rand(N)
colors = np.random.rand(N)
sizes = (30 * np.random.rand(N))**2 # 0 to 15 point radii
plt.scatter(x, y, s=sizes, c=colors, alpha=0.5)
plt.show()
想要获得推送就需要自己写的文章有质量,我做过很多实验,效果很好,下面给大家介绍一下怎么做。
怎么样才能更容易让你的文章更容易获得推送 ?我总结几点 ;
1:原创
想获得平台推送的方法 ,一个很重要的因素就是文章质量高,原创性高,重复度低,
那么是更容易获得推送 ,如果你的文章和已经有发布的文章相似度很高,基本上是很难获得推送的。
2:阅读量
任何一个平台,阅读量,都是一个重要的指标 ,阅读量越高 ,那么就更容易获得平台推送 ,
不管在那个平台,都是一个非常重要的判断指标 。
比如上图 ,这个浏览量越大,说明关心这个话题的人就越多 ,当然文章是没有阅读量的 ,这个后台是有统计的 。
看到这里,聪明的人 ,就有自己的想法了 ,那么是不是自己可以去刷阅读量呢??
这个当然是可以刷的 ,但是刷是需要一定的技术处理的 ,大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!
你手工自己去点 是没有任何意义的 ,这里面包含好几个因素!
第一:IP分布 ,也就是点开你的链接必须是全国各地的Ip,而不是某个省市的IP ,
第二:终端分布 ,包含PC端,安卓端,苹果端
如果都满足了以上因素,那么你就可以刷阅读量 ,如果你对这方面比较感兴趣 ,也可以和我私底下 沟通。
3:评论数量
如果一篇文章,或是问答,下面非常多的评论,哪怕是很没质量,也非常的容易获得推送。
大家如果仔细观察 ,你就会发现 ,有些帖子莫名其妙的火了,虽然他的质量非常的差 ,但是因为评论非常多 。
因为有用户互动,说明这个话题比较具有争议 ,有争议性的东西,对于平台来讲,自然就乐意推送 ,
让大家一起讨论 ,一起争吵 ,所以一篇文章 或是问答写完后 ,
需要用自己的小号,进行助力推送下 ,比如小号引导讨论 ,引导对立 ,这样很多过客,非常容易停留下来 ,
参与到讨论中 ,比如我就很多小号, 几千个 。
做运营,没有号 ,是很难做起来的 ,虽然说方法很多人都知道 ,但是你没有操作起来 ,号太少 ,现在号大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!
非常的便宜,1毛一个 ,如果需要实名身份证这个也是非常容易解决的
4:标题 。
这个老生常谈 ,这个大家可以参考其他的文章 ,都写得非常详细了 ,
我就不多介绍 。
当然还有很多没有讲到的 ,这里就不细说,有兴趣 ,对引流比较感兴趣的 ,
可以一起来沟通学习
参考下图找我交流

open HolKernel boolLib bossLib Parse;open listTheory rich_listTheory arithmeticTheory integerTheory llistTheory pathTheory;open integer_wordTheory wordsTheory pred_setTheory alistTheory;open finite_mapTheory open logrootTheory numposrepTheory set_relationTheory;open sortingTheory;open settingsTheory;new_theory "misc";numLib.prefer_num ();(* Labels for the transitions to make externally observable behaviours apparent.* For now, we'll consider this to be writes to global variables.* *)Datatype:obs =| Tau| W 'a (word8 list)| Exit int| ErrorEndDatatype:trace_type =| Stuck| Complete int| PartialEndInductive observation_prefixes:(∀l i. observation_prefixes (Complete i, l) (Complete i, filter ($≠ Tau) l)) ∧(∀l. observation_prefixes (Stuck, l) (Stuck, filter ($≠ Tau) l)) ∧(∀l1 l2 x.l2 ≼ l1 ∧ (l2 = l1 ⇒ x = Partial)⇒observation_prefixes (x, l1) (Partial, filter ($≠ Tau) l2))EndDefinition take_prop_def:(take_prop P n [] = []) ∧(take_prop P n (x::xs) =if n = 0 then[]else if P x thenx :: take_prop P (n - 1) xselsex :: take_prop P n xs)EndTheorem filter_take_prop[simp]:∀P n l. filter P (take_prop P n l) = take n (filter P l)ProofInduct_on `l` >> rw [take_prop_def]QEDTheorem take_prop_prefix[simp]:∀P n l. take_prop P n l ≼ lProofInduct_on `l` >> rw [take_prop_def]QED(*Theorem take_prop_eq:∀P n l. take_prop P n l = l ∧ l ≠ [] ∧ n ≤ length (filter P l) ⇒ P (last l)ProofInduct_on `l` >> simp_tac (srw_ss()) [take_prop_def] >> rpt gen_tac >>Cases_on `n = 0` >> pop_assum mp_tac >> simp_tac (srw_ss()) [] >>Cases_on `P h` >> pop_assum mp_tac >> simp_tac (srw_ss()) [] >>strip_tac >> strip_tac >>Cases_on `l` >> pop_assum mp_tac >> simp_tac (srw_ss()) []>- metis_tac [take_prop_def] >>ntac 2 strip_tac >> first_x_assum drule >>simp []QED*)Theorem take_prop_eq:∀P n l. take_prop P n l = l ⇒ length (filter P l) ≤ nProofInduct_on `l` >> simp_tac (srw_ss()) [take_prop_def] >> rpt gen_tac >>Cases_on `n = 0` >> pop_assum mp_tac >> simp_tac (srw_ss()) [] >>Cases_on `P h` >> pop_assum mp_tac >> simp_tac (srw_ss()) [] >>strip_tac >> strip_tac >>Cases_on `l` >> pop_assum mp_tac >> simp_tac (srw_ss()) [] >>ntac 2 strip_tac >> first_x_assum drule >> simp []QED(* ----- Theorems about list library functions ----- *)Theorem dropWhile_map:∀P f l. dropWhile P (map f l) = map f (dropWhile (P o f) l)ProofInduct_on `l` >> rw []QEDTheorem dropWhile_prop:∀P l x. x < length l - length (dropWhile P l) ⇒ P (el x l)ProofInduct_on `l` >> rw [] >>Cases_on `x` >> fs []QEDTheorem dropWhile_rev_take:∀P n l x.let len = length (dropWhile P (reverse (take n l))) inx + len < n ∧ n ≤ length l ⇒ P (el (x + len) l)Proofrw [] >>`P (el ((n - 1 - x - length (dropWhile P (reverse (take n l))))) (reverse (take n l)))`by (irule dropWhile_prop >> simp [LENGTH_REVERSE]) >>rfs [EL_REVERSE, EL_TAKE, PRE_SUB1]QEDTheorem take_replicate:∀m n x. take m (replicate n x) = replicate (min m n) xProofInduct_on `n` >> rw [TAKE_def, MIN_DEF] >> fs [] >>Cases_on `m` >> rw []QEDTheorem length_take_less_eq:∀n l. length (take n l) ≤ nProofInduct_on `l` >> rw [TAKE_def] >>Cases_on `n` >> fs []QEDTheorem flat_drop:∀n m ls. flat (drop m ls) = drop (length (flat (take m ls))) (flat ls)ProofInduct_on `ls` >> rw [DROP_def, DROP_APPEND] >>irule (GSYM DROP_LENGTH_TOO_LONG) >> simp []QEDTheorem take_is_prefix:∀n l. take n l ≼ lProofInduct_on `l` >> rw [TAKE_def]QEDTheorem sum_prefix:∀l1 l2. l1 ≼ l2 ⇒ sum l1 ≤ sum l2ProofInduct >> rw [] >> Cases_on `l2` >> fs []QEDTheorem flookup_fdiff:∀m s k.flookup (fdiff m s) k =if k ∈ s then None else flookup m kProofrw [FDIFF_def, FLOOKUP_DRESTRICT] >> fs []QEDTheorem inj_map_prefix_iff:∀f l1 l2. INJ f (set l1 ∪ set l2) UNIV ⇒ (map f l1 ≼ map f l2 ⇔ l1 ≼ l2)ProofInduct_on `l1` >> rw [] >>Cases_on `l2` >> rw [] >>`INJ f (set l1 ∪ set t) UNIV`by (irule INJ_SUBSET >> qexists_tac `(h INSERT set l1) ∪ (set (h'::t))` >>simp [SUBSET_DEF] >> fs [] >>metis_tac []) >>fs [INJ_IFF] >> metis_tac []QEDTheorem is_prefix_subset:∀l1 l2. l1 ≼ l2 ⇒ set l1 ⊆ set l2ProofInduct_on `l1` >> rw [] >>Cases_on `l2` >> fs [SUBSET_DEF]QEDTheorem mem_el_front:


相关文章
-
![[新闻直播间]巴黎系列恐怖袭击事件 多国民众哀悼恐怖袭击遇难者_CCTV节目官网-CCTV-13_央视网(cctv.com)](https://pybyzl.com/zb_users/theme/zblogsm_com/include/post-load.gif)
[新闻直播间]巴黎系列恐怖袭击事件 多国民众哀悼恐怖袭击遇难者_CCTV节目官网-CCTV-13_央视网(cctv.com)
-
C罗欧洲杯恐进超级死亡之组!葡萄牙+德国+法国?_国际足球_新浪竞技风暴_新浪网
-
[女足]阿尔加夫杯C组第1轮:荷兰VS中国 上半场_体育_央视网(cctv.com)
-
6月28日—7月11日央视网全程视频直播2021温网
-
2023任贤齐演唱会-郑州站,10月14日精彩演出即将开启!_手机搜狐网
-
推出半年用户破千万 唱吧的收费模式可行吗?
-
欧洲杯直播-欧洲杯在线直播观看-欧洲杯高清直播(无插件)直播-欧洲足球直播免费-24小时在线直播视频免费-360直播吧
-
明年深圳见!盘点女篮亚洲杯的“前世今生”_南方网
![[新闻直播间]巴黎系列恐怖袭击事件 多国民众哀悼恐怖袭击遇难者_CCTV节目官网-CCTV-13_央视网(cctv.com)](https://pybyzl.com/zb_users/cache/thumbs/13fb37c7608adee473e511ebd0be2e8f-190-120-1.jpg)

![[女足]阿尔加夫杯C组第1轮:荷兰VS中国 上半场_体育_央视网(cctv.com)](https://pybyzl.com/zb_users/cache/thumbs/8224d9d54561c9a7cf180e61cc3a2856-190-120-1.jpg)





评论